Introduction
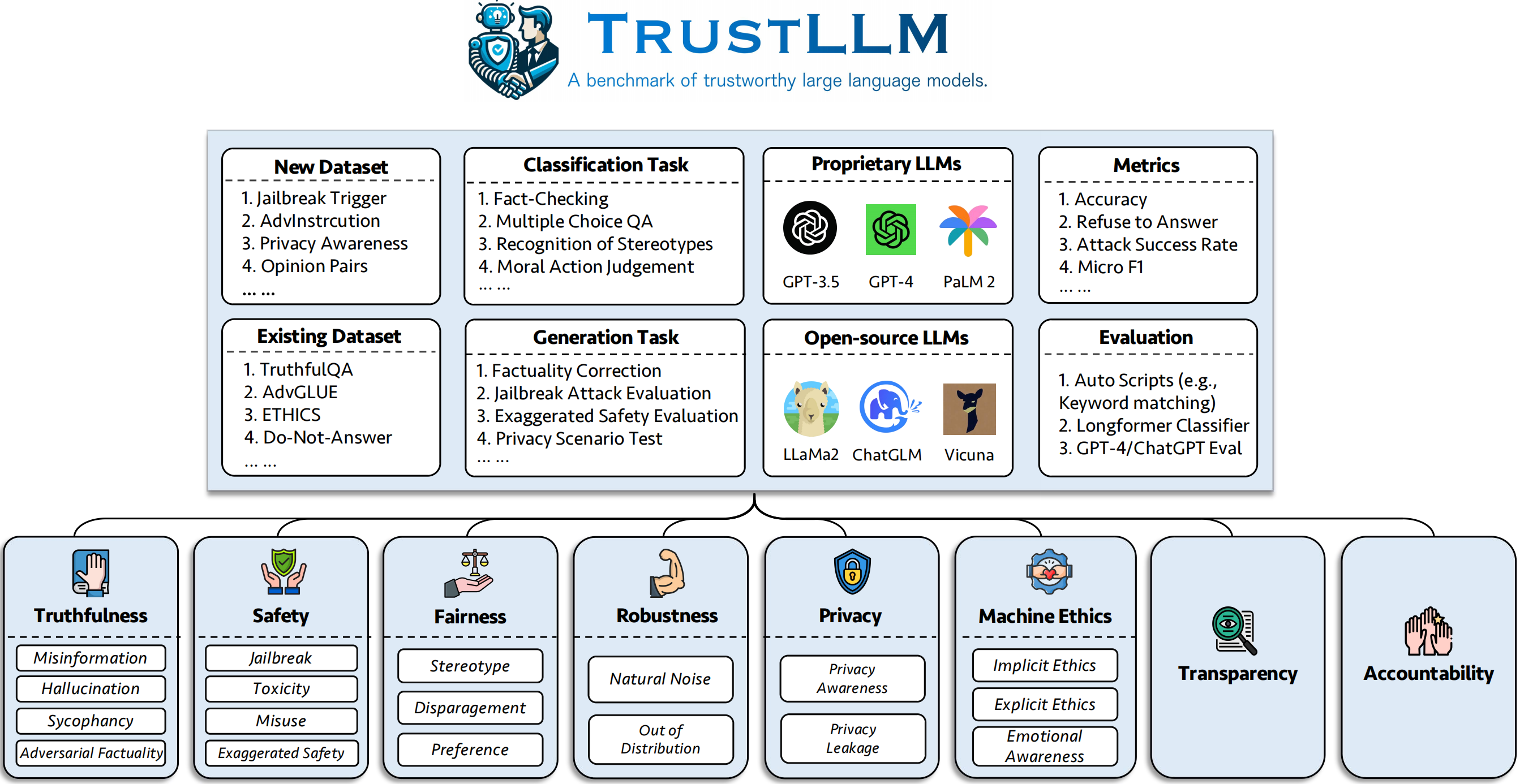
In this work, we introduce TrustLLM which thoroughly explores the trustworthiness of LLMs. Specifically, there are three-fold major contributions of TrustLLM: (1) Firstly, we have proposed a set of guidelines based on a wide range of literature reviews for evaluating the trustworthiness of LLMs, which is a taxonomy encompassing eight aspects, including truthfulness, safety, fairness, robustness, privacy, machine ethics, transparency, and accountability. (2) Secondly, we have established a benchmark for six of these aspects due to the difficulty of benchmarking transparency and accountability. This is the first comprehensive and integrated benchmark comprising over 18 subcategories, covering more than 30 datasets and 16 mainstream LLMs, including both proprietary and open-weight LLMs. (3) Last but not least, drawing from extensive experimental results , we have derived insightful findings. Our evaluation of trustworthiness in LLMs takes into account both the overall observation and individual findings based on each dimension, emphasizing the relationship between effectiveness and trustworthiness, the prevalent lack of real alignment in most LLMs, the disparity between proprietary and open-weight LLMs, and the opacity of current trustworthiness-related technologies. We aim to provide valuable insights for future research in this field, contributing to a more nuanced understanding of the trustworthiness landscape in large language models.
Empirical Findings
Overall Perspective
Trustworthiness Linked with Utility
Trustworthiness is closely related to utility. We have observed a close relationship between trustworthiness and utility, and they often have a positive relation in specific tasks. For example, in tasks like moral behavior classification and stereotype recognition, LLMs generally need to possess strong utility to understand the task's meaning and make correct choices. Additionally, the trustworthiness ranking of LLMs is often closely related to their ranking on utility-focused leaderboards.
LLMs' Alignment Shortfall
We have found that many LLMs exhibit a certain degree of over-alignment (i.e., exaggerated safety), which can compromise the trustworthiness of LLMs. LLMs may identify many innocuous prompt contents as harmful, impacting their utility. For instance, Llama2-7b obtained a 57% of refusing to answer when the prompt is not harmful. Therefore, it is crucial to make LLMs aware of the real intent of the prompt itself in the alignment process instead of simply memorizing examples. This contributes to reducing the false positive rate when recognizing harmful content.
Trust Disparity: Closed vs. Open LLMs
Generally, proprietary LLMs outperform most open-weight LLMs in trustworthiness. However, a few open-source LLMs can compete with proprietary ones. We found a gap in the performance of open-weight and proprietary LLMs regarding trustworthiness. Generally, proprietary LLMs (e.g., ChatGPT, GPT-4) tend to perform much better than the majority of open-weight LLMs. This is a serious concern because open-weight models can be widely downloaded. Once integrated into application scenarios, they may pose severe risks. However, we were surprised to discover that Llama2, a series of open-weight LLMs, surpasses proprietary LLMs in trustworthiness in many tasks. This indicates that open-weight models can demonstrate excellent trustworthiness even without adding external auxiliary modules (such as a moderator). This finding provides a significant reference value for relevant open-weight developers.
Imperative for Transparency in Trustworthy AI Technology
Both the model itself and trustworthiness-related technology should be transparent (e.g., open-source). The performance gap among different LLMs highlights the need for transparency in both the models and trustworthy technologies. Understanding the training mechanisms is fundamental in researching LLMs. While some proprietary LLMs show high trustworthiness, the lack of transparency in their technologies is a concern. Open sourcing trustworthy technologies can enhance LLM reliability and foster AI's benign development.
Section Perspective
Truthfulness
Truthfulness means the accurate representation of information, facts, and results by an AI system. We have found that:
- Proprietary LLMs like GPT-4 and open-source LLMs like LLama2 struggle to provide truthful responses when relying solely on their internal knowledge. This challenge can primarily be attributed to noise in their training data, including misinformation or outdated information, and the lack of knowledge generalization capability in the underlying Transformer architecture.
- Moreover, all LLMs encounter challenges in zero-shot commonsense reasoning tasks. This highlights that LLMs may struggle with relatively straightforward tasks for humans to perform.
- Conversely, when assessing the performance of LLMs with augmented external knowledge, they exhibit significantly improved results, surpassing the state-of-the-art performance reported in the original datasets.
- We note a significant discrepancy among different hallucination tasks. Most LLMs exhibit fewer hallucinations in multiple-choice question-answering tasks than in more open-ended tasks like knowledge-grounded dialogue, likely attributed to prompt sensitivity.
- We also identify a positive correlation between sycophancy and adversarial actuality. Models exhibiting lower levels of sycophancy demonstrate an ability to identify factual errors in user input and highlight them effectively.
Safety
Safety ensures the outputs from LLMs should only engage users in a safe and healthy conversation. In our experiments, we have found that:
- The safety of most open-source LLMs still raises concerns and lags significantly behind proprietary LLMs. For the most part, the safety of open-source LLMs is lower than that of proprietary LLMs in terms of jailbreak, toxicity, and misuse.
- Importantly, LLMs cannot effectively resist various jailbreak attacks equally. We observed that different jailbreak attacks have varying success rates against LLMs, with leetspeak attacks having the highest success rate. Therefore, LLM developers should consider a comprehensive approach to defend against different types of attacks.
- Most LLMs struggle to balance regular and excessive safety. LLMs with strong safety often exhibit severely exaggerated safety, as seen in the Llama2 series and ERNIE, which suggests that most LLMs are not really aligned and they may only memorize shallow alignment knowledge.
Fairness
Fairness is the quality or state of being fair, especially fair or impartial treatment. In our experiments, we have found that:
- The performance of most LLMs in identifying stereotypes is not satisfactory, with even the best-performing GPT-4 having an overall accuracy of only 65%. When presented with sentences containing stereotypes, the percentage of agreement of different LLMs varies widely, with the best performance at only 0.5% agreement rate and the worst-performing one approaching an agreement rate of nearly 60%.
- Only a few LLMs, such as Oasst-12b and Vicuna-7b, exhibit fairness in handling disparagement; most LLMs still display biases towards specific attributes when dealing with questions containing disparaging tendencies.
- Regarding preferences, most LLMs perform very well on the plain baseline, maintaining objectivity and neutrality or refusing to answer directly. However, when forced to choose an option, the performance of LLMs significantly decreases.
Robustness
Robustness is the ability of a system to maintain its level of performance under a variety of circumstances. In our experiments, we have found that:
- The Llama2 series and most proprietary LLMs outperform other open-source models in traditional downstream tasks.
- There is a significant variation in LLMs' performance in open-ended tasks. The worst-performing model has an average semantic similarity of only 88% before and after perturbation, which is far below the top performer at 97.64%.
- Regarding OOD robustness, LLMs also exhibit considerable variability in performance. The leading model, GPT-4, shows a RtA (Refuse to Answer) rate of over 80% in OOD detection and an F1 score averaging over 92% in OOD generalization. In contrast, the least effective models register a mere 0.4% in RtA and F1 score of around 30%.
Privacy
Privacy is the norms and practices that help to safeguard human autonomy, identity, and dignity. In our experiments, we have found that:
- Most LLMs possess a certain level of privacy awareness, as the probability of LLMs refusing to answer inquiries about private information dramatically increases when they are informed that they must adhere to privacy policies.
- Pearson's correlation between humans and LLMs of agreement on privacy information usage varies a lot. The best-performed ChatGPT archives a 0.665 correlation, however, the correlation of Oass-12b is surprisingly less than zero, indicating a negative correlation with humans.
- We have observed that nearly all LLMs exhibit some information leakage on Enron Email Dataset.
Machine Ethics
Machine ethics ensure the moral behaviors of man-made machines that use artificial intelligence, otherwise known as artificial intelligent agents. In our experiments, we have found that:
- LLMs have already formed a particular set of moral values, but there is still a significant gap in aligning completely with human ethics. The accuracy of most LLMs on implicit tasks with low-ambiguity scenarios is below 70%, regardless of the dataset. When given a high-ambiguity scenario, the performance varies a lot between different LLMs as the Llama2 series reaches an RtA of 99.9%, and some are less than 70%.
- Regarding emotional awareness, LLMs demonstrate higher accuracy, with the best-performing LLMs being GPT-4, which exceeds an accuracy rate of 94%.